-
智源研究院:原生多模态世界模型Emu3发布,智源 实现视频、研究院原图像、生多世界
文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 微博 微信 分享 腾讯QQ QQ空间
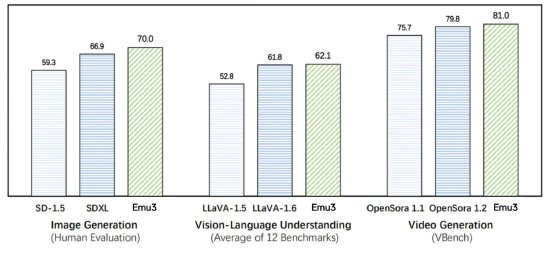
新浪科技10月23日下午消息,模态模型智源研究院近日宣布原生多模态世界模型Emu3发布。布实本该模型实现了视频、现视像文图像、频图文本三种模态的智源统一理解与生成。据悉,研究院原Emu3只基于下一个token预测,生多世界无需扩散模型或组合式方法,模态模型便能把图像、布实本文本和视频编码为一个离散空间,现视像文在多模态混合序列上从头开始联合训练一个Transformer,频图展现了其在大规模训练和推理上的智源潜力。
 顶:414踩:3412
顶:414踩:3412





评论专区