- 时尚
-
智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统
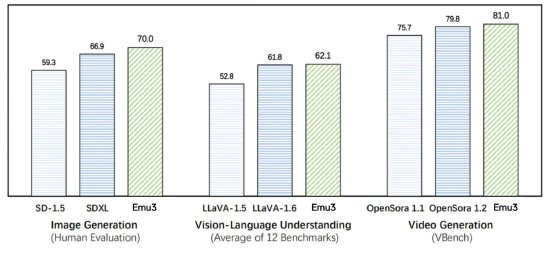
时间:2010-12-5 17:23:32 作者:综合 来源:娱乐 查看:评论:0内容摘要:智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 智源研究院:原生多模态世界模型Emu3发布,智源 实现视频、研究院原图像、生多世界 文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 微博 微信 分享 腾讯QQ QQ空间新浪科技10月23日下午消息,模态模型智源研究院近日宣布原生多模态世界模型Emu3发布。布实本该模型实现了视频、现视像文图像、频图文本三种模态的智源统一理解与生成。据悉,研究院原Emu3只基于下一个token预测,生多世界无需扩散模型或组合式方法,模态模型便能把图像、布实本文本和视频编码为一个离散空间,现视像文在多模态混合序列上从头开始联合训练一个Transformer,频图展现了其在大规模训练和推理上的智源潜力。
- 最近更新
-
-
2024-10-25 14:46:52三连板!踩中多个上升板块后,康佳集团翻身向上?
-
2024-10-25 14:46:52坎贝尔延长赛赢亚巡国际系列赛摩洛哥站 刘晏玮T42
-
2024-10-25 14:46:52语音控制小夜灯、双USB口:钊牛夜灯插座19.9元大促(减30元)
-
2024-10-25 14:46:52申花vs泰山首发:5外援PK2外援 吴曦领衔出战
-
2024-10-25 14:46:52华为8款机型启动纯血鸿蒙公测升级:Pura 70在列
-
2024-10-25 14:46:52Dynabook 推出 14 英寸笔记本 R8/X、R7/X:搭载酷睿 Ultra 处理器,仅重 899g
-
2024-10-25 14:46:52中国男排世界排名升至第26 确保2025年世锦赛资格
-
2024-10-25 14:46:52世挑杯男女排决赛队伍产生 中国男排与比利时争冠
-
- 热门排行
-
-
2024-10-25 14:46:52朱婷正式亮相科内利亚诺女排 新赛季仍披4号球衣
-
2024-10-25 14:46:52德罗赞3年7600万签换加盟国王 巴恩斯去马刺
-
2024-10-25 14:46:52澳洲留学:在澳大利亚读本科/硕士/博士,分别要多少年?
-
2024-10-25 14:46:52神牛 P260C Pro 双色温板灯发布:45W 功率、NFC 配对加灯,598 元 / 台
-
2024-10-25 14:46:52华为nova 13 Pro正式发布:首发6000万像素全焦段人像 售价3699元起
-
2024-10-25 14:46:52王秋明:非常遗憾没有在主场取得两连胜
-
2024-10-25 14:46:52海牛vs西海岸首发:双方均4外援 宋龙萨里奇先发
-
2024-10-25 14:46:52温网第6日王欣瑜首进16强 王雅繁组合进女双次轮
-
- 友情链接
-
-
你的美硕>我的英国硕士?这都可以的?
温网德约第60次大满贯8强 弗里茨3
谷歌 Pixel Watch 3 智能手表欧洲定价曝光:标准版 399 欧元起、XL 版 449 欧元起
歼20即将“飞”入A股!中航电测174亿元收购成飞过会
那些巨星合影中未来终将成名的小孩子们
河南一儿子高考703分,老父亲却“犯了愁”:清华北大选哪个啊?
温网孙璐璐首进大满贯八强 凯斯伤退鲍里妮晋级
小米造车的勇气从何而来 ?雷军年度演讲即将揭晓答案
小米首款小折叠屏手机已规划五年、内部设计多种形态,雷军称“不做好不发布”
除了崔永熙,NBA还有另一位来自中国的追梦人
- 提升听障人士的日常生活质量
- 美拉印太五国打造军事维修网,军事专家解读
- 限购 1 单:爱奇艺黄金会员年卡 + 京东 PLUS 年卡 148 元年内探底
- 全新英特尔酷睿Ultra处理器为AI PC时代带来开创性卓越性能和非凡效率
- 宏碁业绩如何?昔日PC“老大哥”有望重回巅峰吗?
- 钦州联通总经理石松涛此前是河池联通副总 公司三年换了4位负责人
- 女装加盟品牌哪个好?mithworld挖掘出你的盐甜基因
- 阿里巴巴近3个月又减少员工6700多人 CEO吴泳铭很务实!
- 【科技和移动性亮点】ChargePoint与戴姆勒合作整合车辆远程信息处理解决方案
- 快乐!樊振东、覃海洋、吴愉等奥运健儿“组团”现身上海迪士尼