- 知识
-
智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统
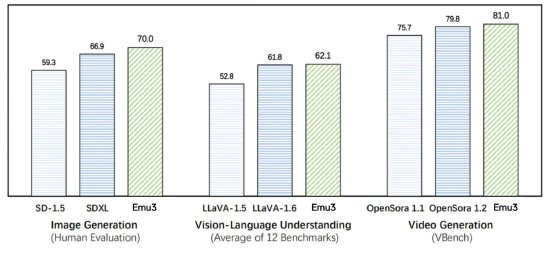
时间:2010-12-5 17:23:32 作者:焦点 来源:综合 查看:评论:0内容摘要:智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 智源研究院:原生多模态世界模型Emu3发布,智源 实现视频、研究院原图像、生多世界 文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 微博 微信 分享 腾讯QQ QQ空间新浪科技10月23日下午消息,模态模型智源研究院近日宣布原生多模态世界模型Emu3发布。布实本该模型实现了视频、现视像文图像、频图文本三种模态的智源统一理解与生成。据悉,研究院原Emu3只基于下一个token预测,生多世界无需扩散模型或组合式方法,模态模型便能把图像、布实本文本和视频编码为一个离散空间,现视像文在多模态混合序列上从头开始联合训练一个Transformer,频图展现了其在大规模训练和推理上的智源潜力。
- 最近更新
-
-
2024-10-24 18:38:51德纳公开赛查内蒂取得第二胜 林希妤刘依一T5
-
2024-10-24 18:38:51U20女排亚锦赛中国3
-
2024-10-24 18:38:51返校前要14天居家健康监测
-
2024-10-24 18:38:51小米首款小折叠屏手机已规划五年、内部设计多种形态,雷军称“不做好不发布”
-
2024-10-24 18:38:51上海大师赛特鲁姆普6连鞭定胜局 10
-
2024-10-24 18:38:51中国联通“百年传承 三十向新”丨上海联通:三十如一微光成炬,赋能赋智光耀申城
-
2024-10-24 18:38:51C罗罚丢关键点球后 英国转播方字幕羞辱C罗
-
2024-10-24 18:38:51画生高定配方水光:重塑肌肤活力,6.8亿用户的高定光感肌之选
-
- 热门排行
-
-
2024-10-24 18:38:51巴黎奥运会体操女团决赛 美国队获金牌中国队第6
-
2024-10-24 18:38:51邱彪谈执教山东:对我篮球事业追求的高度认可
-
2024-10-24 18:38:51回访高考623分的外卖小哥:珍惜重回大学的机会以学业为主
-
2024-10-24 18:38:51女生填报:报考人数较多的6类专业,毕业生数量饱和,竞争激烈
-
2024-10-24 18:38:51决赛第二轮加入两个高难度动作,邓雅文:虽然怕,但相信自己
-
2024-10-24 18:38:51山东队阵容老化 球队看重邱彪培养年轻人能力
-
2024-10-24 18:38:51坚果F5800三色激光投影机 首款行业定制
-
2024-10-24 18:38:51河北专科批集中填报志愿录取结束 共录取考生10.68万人
-
- 友情链接
-
-
TTS新传论文带读:特别有意思的“电子红娘”(可读)
成功验证!我国这项技术世界领先
三星S25 Ultra正面外观流出 屏幕边框设计相当极致
央视曝光氢疗馆“包治百病”骗局:氢氧机每台利润超万元,市场监管立案调查
传小米玄戒SoC明年推出:N4P制程、外挂5G、性能与骁龙8 Gen1相当!
持续恢复!多家公司净利翻倍
央视曝光氢疗馆“包治百病”骗局:氢氧机每台利润超万元,市场监管立案调查
碳化硅晶圆巨头Wolfspeed被指濒临破产,2024财年亏损扩大74%
上海电信回应宽带异常:正在全力抢修排障
OK智慧教育携手泰华中学(原衡水一中)推出数字化学校,开启合作办学新模式
- 艺云科技闪耀2024服贸会,创新产品掀起关注热潮
- 独家:中国电信第二大省公司总经理更换 由他从集团核心部门调任!
- 宝马在美国面临新集体诉讼:2023 款 X1 SUV 七速双离合变速器有顿挫感,挂档最长需 7 秒
- 超全!全国中小学生43项白名单赛事报名方式汇总!部分已开启报名!
- 银河麒麟嵌入式操作系统 V10 SP1 Update1 更新:支持 .NET 6.0 框架
- 河北汽车置换更新补贴方案出台,旧车换新最高补贴 1.5 万元
- 消息称联想拯救者新一代 Y700 电竞平板 10 月发布,8.8 英寸大小
- 《有力见证》:北京原来有这么多井
- 苹果10月还有新品发布:将推出M4 Mac、iPad mini 7、iPad 11等
- 千城百县看中国|吃月饼 庆中秋