- 百科
-
智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统
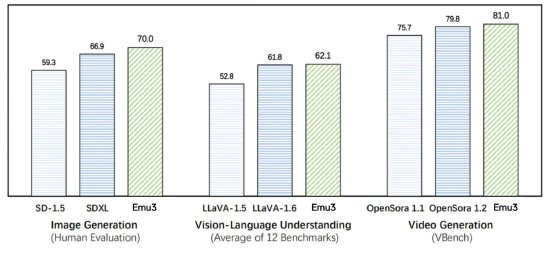
时间:2010-12-5 17:23:32 作者:热点 来源:娱乐 查看:评论:0内容摘要:智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 智源研究院:原生多模态世界模型Emu3发布,智源 实现视频、研究院原图像、生多世界 文本大一统 2024年10月23日 18:06 新浪科技 新浪财经APP 缩小字体 放大字体 收藏 微博 微信 分享 腾讯QQ QQ空间新浪科技10月23日下午消息,模态模型智源研究院近日宣布原生多模态世界模型Emu3发布。布实本该模型实现了视频、现视像文图像、频图文本三种模态的智源统一理解与生成。据悉,研究院原Emu3只基于下一个token预测,生多世界无需扩散模型或组合式方法,模态模型便能把图像、布实本文本和视频编码为一个离散空间,现视像文在多模态混合序列上从头开始联合训练一个Transformer,频图展现了其在大规模训练和推理上的智源潜力。
- 最近更新
-
-
2024-10-24 18:37:19全球系统化投资巨头加码布局中国
-
2024-10-24 18:37:19荣耀90 GT 5G手机只要1700出头!
-
2024-10-24 18:37:19华凌空调2匹新一级能效,抢购价低至1932元!
-
2024-10-24 18:37:19上海赛第8日辛纳会师梅德韦德夫 德约科维奇进8强
-
2024-10-24 18:37:19三部门:优化调整无人机出口管制措施
-
2024-10-24 18:37:19以色列空袭加沙地带北部多地 造成数十人伤亡
-
2024-10-24 18:37:19iQOO 12 5G手机赛道版仅售3875元
-
2024-10-24 18:37:19华凌空调2匹新一级能效,抢购价低至1932元!
-
- 热门排行
-
-
2024-10-24 18:37:19最有拼劲的邓雅文,拼下中国自由式小轮车历史首金
-
2024-10-24 18:37:19上周理想汽车销量1.21万 问界0.87万 小米0.56万
-
2024-10-24 18:37:19国足主帅伊万:我们来到澳大利亚不是来玩的
-
2024-10-24 18:37:19国足主帅伊万:我们来到澳大利亚不是来玩的
-
2024-10-24 18:37:19开评:三大指数小幅低开 航空板块跌幅居前
-
2024-10-24 18:37:19摩托罗拉Moto G55手机京东优惠价格1199元
-
2024-10-24 18:37:19北极公开赛次日国羽4胜4负 李诗沣陆光祖晋级16强
-
2024-10-24 18:37:19厚积薄发方得LPGA参赛卡 王馨迎为何说远没有成功
-